Increasing the Value of Information During Planning in Uncertain Environments
Author: Gaurab Pokharel
Type: Undergraduate Honors Thesis (May 2021)
Overview
When planning under uncertainty, it’s often optimal to gather information early—even if that delays task completion—because better information enables better downstream choices. In POMDPs, this is the value of information (VOI).
However, many online planners struggle in an important regime: when there is a large time delay between (1) taking an information-gathering action and (2) the point where that information pays off. In these settings, information-gathering actions can be critical in the optimal policy but are often ignored during online search, leading to suboptimal decision-making.
This thesis proposes a simple, computationally cheap fix: bias online Monte Carlo planning toward actions that reduce uncertainty, so the planner doesn’t “miss” crucial information-gathering detours.
Background: POMDP Planning and Why VOI Gets Missed
Online POMDP planners build a look-ahead tree from the agent’s current belief state and use limited computation to estimate action values. Methods like POMCP use Monte Carlo rollouts and a UCB-style heuristic to balance exploration and exploitation.
The failure mode is intuitive:
- Information-gathering actions often have no immediate reward.
- If the benefit only appears many steps later, the planner must sample very specific long trajectories to realize the payoff.
- With limited planning time and biased sampling, the planner may never explore the “right” long path often enough to recognize its value.
Key Idea: Entropy-Augmented UCB in POMCP (POMCPe)
We modify POMCP’s node-selection heuristic by adding an entropy reduction term. Entropy provides a direct measure of uncertainty in the agent’s belief. The intuition is:
Actions that reduce belief entropy are good candidates for high VOI, especially when rewards are delayed.
A high-level version of the idea is:
- Keep the standard UCB1 optimism term for reward.
- Add an entropy-driven term that favors actions whose subtree yields large reductions in belief uncertainty.
- Decay the influence of the entropy term as the search gathers more samples, so values still converge toward reward-maximization.
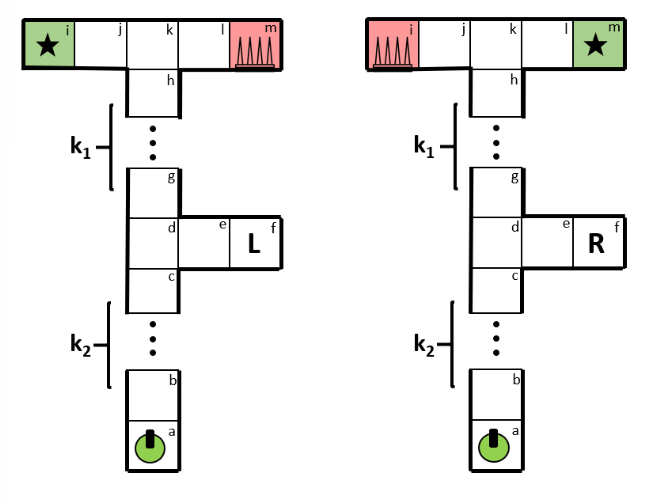
Benchmark: The Long Hallway Domain
To stress-test delayed information value, the thesis introduces a “Long Hallway” benchmark—a harder variant of the classic hallway problem.
There are two visually identical hallways with the goal and trap swapped. The agent must choose left vs right near the end, but can only disambiguate which hallway it is in by taking an early detour down a side corridor that provides a special observation. Crucially, there is a tunable delay between:
- when the agent can gather that observation, and
- when it needs to exploit it to avoid the trap and reach the goal.
Results (Summary)
Across experimental settings, entropy-augmented planning (POMCPe) substantially improves the likelihood that the agent takes the early detour, resolves uncertainty, and reaches the goal.
Key comparison highlights$
- In the baseline Long Hallway setting ($K_1=K_2=1$), POMCPe achieves much higher discounted and cumulative reward than POMCP.
- In a modified start state where the information-gathering detour is only one step away, POMCP still performs poorly while POMCPe reliably resolves uncertainty first.
- In a larger hallway ($K_1=K_2=2$), POMCPe continues to reach the +100 goal much more often than POMCP, though it can spend extra time wandering, reducing discounted reward.
Takeaways
- Delayed VOI is a real planning failure mode: actions that are crucial in the optimal policy can be ignored under time-limited Monte Carlo planning.
- Entropy is a useful proxy for VOI: when information is valuable but its payoff is delayed, reducing uncertainty becomes a strong search signal.
- The modification is lightweight: the goal is to improve performance without sacrificing the anytime nature of online planning.
Acknowledgements
This thesis was completed with support from the Oberlin College Computer Science Department and guidance from Dr. Adam Eck.
Citation
@misc{Pokharel_2024,
title={Increasing the Value of Information During Planning in Uncertain Environments},
url={https://arxiv.org/abs/2409.13754v1},
journal={arXiv.org},
author={Pokharel, Gaurab},
year={2024},
month=sept,
language={en}
}