Converging to Stability in Two-Sided Bandits: The Case of Unknown Preferences on Both Sides of a Matching Market
Authors: Gaurab Pokharel¹, and Sanmay Das¹
Affiliations: ¹Virginia Tech
Overview
Classic matching-market mechanisms (e.g., Gale–Shapley) assume agents know their preferences. In many real deployments, preferences must be learned from experience: repeated interactions reveal noisy signals about match quality, and agents must decide whom to propose to while anticipating competition and acceptance.
This project studies two-sided bandits: repeated matching where proposers must learn rewards for different partners and must reason about whether a proposal will be accepted—because acceptance depends on the receiving side’s preferences and other agents’ competing proposals.
Setting (Players, Arms, and Stability)
At each round, each player proposes to an arm. Arms receive one or more proposals and choose at most one to accept; successful matches generate stochastic rewards and update beliefs. The goal is to converge to a stable matching, where no blocking pair prefers each other over their current matches.
We consider three information regimes:
- APCK (Arm Preferences Common Knowledge): arms’ preferences are known and common knowledge.
- APKP (Arm Preferences Known but Private): arms know their preferences, but players do not.
- APU (Arm Preferences Unknown): arms also learn their preferences from interaction.
Algorithms
Baseline: CA-UCB (APCK)
When arm preferences are common knowledge, players can construct a “plausible set” of arms they could realistically win and propose using UCB-style optimism, avoiding unnecessary conflicts.
OCA-UCB (APKP)
When arm preferences are private, players maintain optimistic beliefs about how arms rank them, and update those beliefs using minimal conflict feedback (who won a contested arm). This recovers a conflict-avoiding behavior similar to CA-UCB while learning arms’ rankings over time.
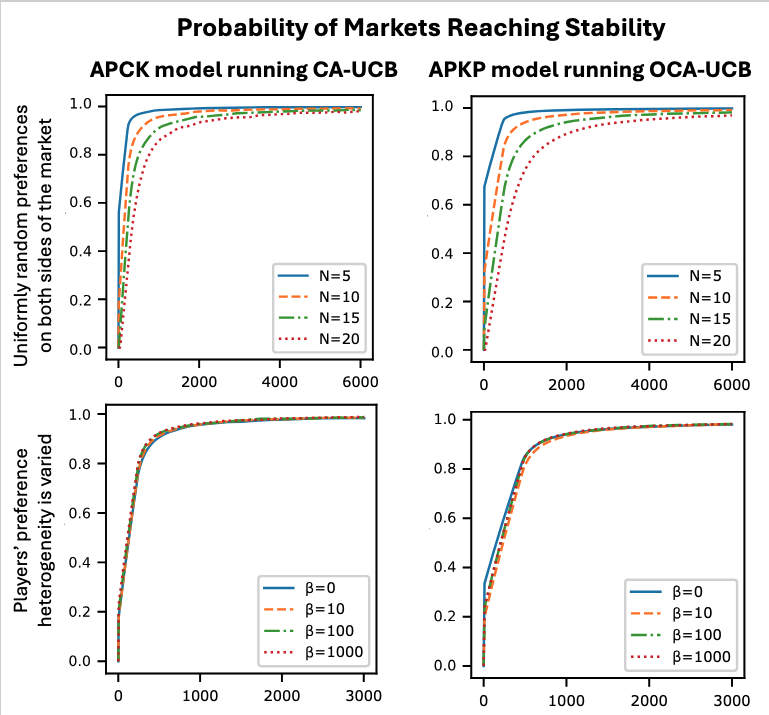
PCA-SCA (APU)
When arms themselves do not know their preferences, conflict outcomes are initially noisy. PCA-SCA handles this by:
- having arms maintain reward estimates and confidence intervals over players,
- resolving overlaps probabilistically early on,
- having players choose arms by combining (i) reward optimism and (ii) optimistic estimates of win probability in contested proposals.
The framework supports both UCB-style and Thompson-style belief tracking.
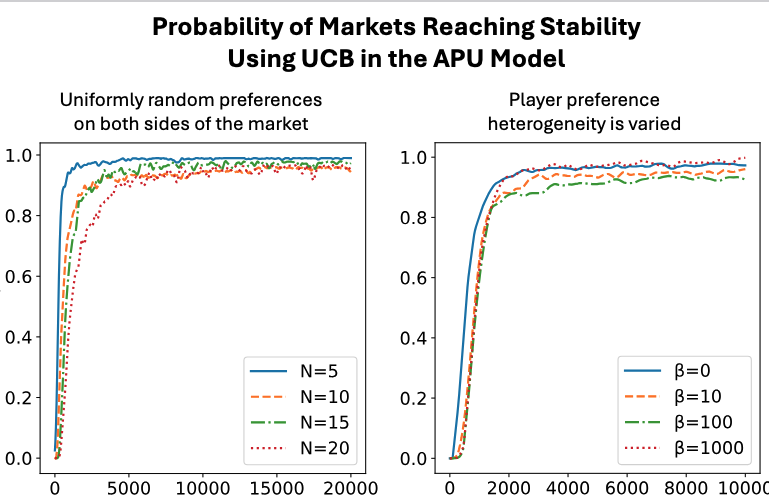
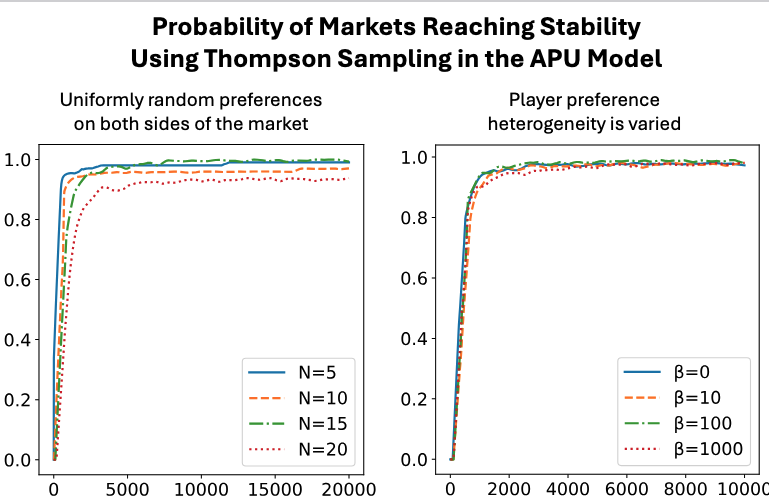
Theory Highlights (High-Level)
- In APKP, optimistic belief updates are enough to preserve convergence guarantees similar to the common-knowledge case.
- In APU, as arms learn and their confidence intervals separate, feedback becomes effectively deterministic; players’ win-probability estimates converge, and the resulting behavior becomes equivalent to the idealized conflict-avoiding execution in the limit.
Simulation Takeaways
Across market sizes and preference heterogeneity:
- The proposed algorithms converge toward stable matchings.
- Player regret declines as learning progresses.
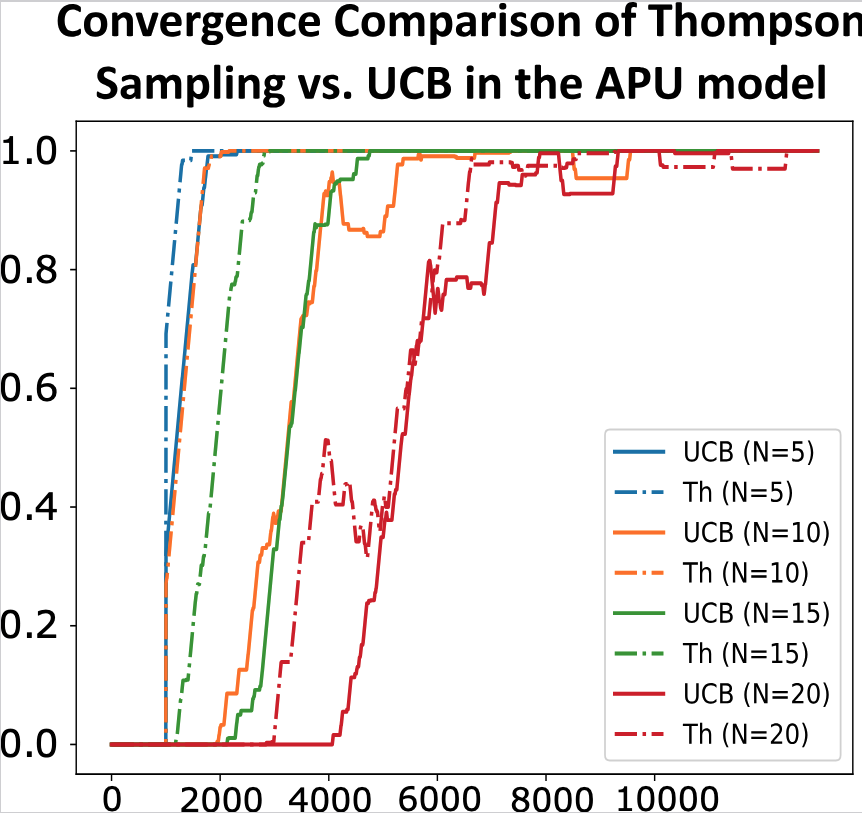
- In the fully-unknown APU model, Thompson Sampling often converges faster and more smoothly than UCB.
Visualization of the Optimism Function
Why this matters
Learning in matching markets shows up in hiring pipelines, internships/residencies, platform matching, and school choice variants where preferences are implicit and noisy. This project offers a principled route to decentralized, no-explicit-communication learning dynamics that still converge to stable outcomes, even when both sides begin uncertain.
Citation
@article{Pokharel_Das_2023,
title={Converging to Stability in Two-Sided Bandits:
The Case of Unknown Preferences on Both Sides of a Matching Market},
url={http://arxiv.org/abs/2302.06176},
DOI={10.48550/arXiv.2302.06176},
note={arXiv:2302.06176 [cs]},
number={arXiv:2302.06176},
publisher={arXiv},
author={Pokharel, Gaurab and Das, Sanmay},
year={2023},
month=feb
}