Street-Level AI: Are Large Language Models Ready for Real-World Judgments?
Authors: Gaurab Pokharel¹, Shafkat Farabi¹, Patrick J. Fowler², and Sanmay Das¹
Affiliations: ¹Virginia Tech, ²Washington University in St. Louis
Venue: Proceedings of the Eighth AAAI/ACM Conference on AI, Ethics, and Society (AIES 2025)
Overview
As Large Language Models (LLMs) are increasingly touted for their ability to streamline human work, they are likely to see rapid uptake in domains involving the allocation of scarce societal resources. In this paper, we explore whether LLMs are ready to replace or supplement "street-level bureaucrats"—the individuals tasked with deciding how to allocate scarce social resources or approve benefits.
We ground our inquiry in the domain of homelessness resource allocation. Using real-world data from St. Louis, we examine how well LLM judgments align with human assessments and the socially and politically determined vulnerability scoring systems currently in use.
Key Takeaway: Our findings call into question the readiness of current generation AI systems for naive integration in high-stakes societal decision-making. While LLMs demonstrate qualitative consistency with lay human judgments in simple testing, their prioritizations are extremely inconsistent when applied to real-world data.
Methodology
We designed two complementary experimental tasks to assess LLM alignment with human judgments and established scoring systems:
1. Pairwise Comparisons
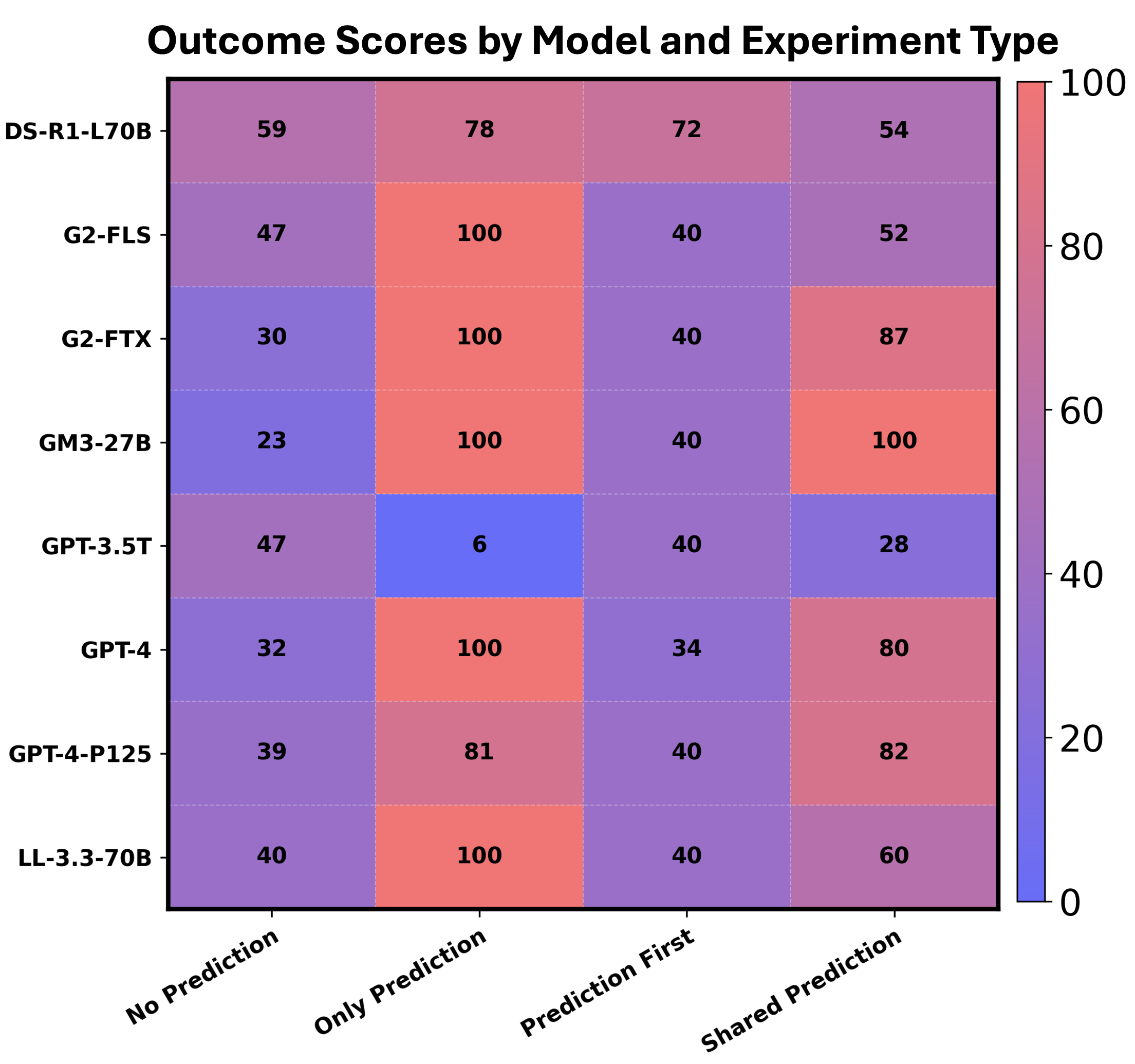
We replicated an experiment using 10 pairs of household data (including demographics, income, and disability status) drawn from homelessness service records. Models were asked to prioritize one household for Transitional Housing (intensive support) while the other received an Emergency Shelter (less intensive overnight stay). We tested models under four information conditions:
- No Prediction: The model sees only the household data table.
- Only Prediction: The model sees only the outcome prediction.
- Prediction First: The model generates its own outcome prediction before making the allocation decision.
- Shared Prediction: The model sees both the data table and a pre-computed "outcome prediction" risk score.
2. Ranking Task
We elicited pairwise prioritization comparisons from LLMs to create a complete ranked list of households for prioritization using the Rank Centrality algorithm. These rankings were compared against established bureaucratic assessment tools, such as the VI-SPDAT (Vulnerability Index-Service Prioritization Decision Assistance Tool) and the RMFS (Risk/Medical Frailty Score).

Key Findings
Internal Inconsistency
LLMs failed to produce stable vulnerability orderings. Spearman correlation coefficients between independent runs of the same model on the exact same data ranged from near zero to only moderate, indicating that two executions can generate markedly different rankings.
Misalignment with Established Systems
LLM-generated rankings showed near-zero correlation with the vetted bureaucratic scoring systems (VI-SPDAT and RMFS) adopted in coordinated entry systems.
Weak Predictive Validity for Human Decisions
When tested against actual service receipt data, LLM rankings were weak predictors of whether a household actually received intensive services. LLMs offered no improvement over existing tools in forecasting real-world decisions made by human experts.
Inconsistent Decision Criteria
Regression analysis showed that LLMs focused on different question-answer pairs across different runs. For instance, models were inconsistently influenced by "No answer" responses in questionnaires and showed varying polarities for the same features (like current living arrangements).
Conclusion
Our study cautions against the wholesale replacement of street-level bureaucrats with off-the-shelf LLMs. Without domain-specific adaptation, these models fail to capture the local justice principles and context-sensitive discretion essential for equitable public service. Future AI integration must focus on hybrid systems where machine recommendations are transparent, consistently calibrated, and subject to professional human oversight.
Citation
@article{Pokharel_Farabi_Fowler_Das_2025,
title={Street-Level AI: Are Large Language Models Ready for Real-World Judgments?},
volume={8},
ISSN={3065-8365},
url={https://ojs.aaai.org/index.php/AIES/article/view/36694},
DOI={10.1609/aies.v8i3.36694},
number={3},
journal={Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society},
author={Pokharel, Gaurab and Farabi, Shafkat and Fowler, Patrick J. and Das, Sanmay},
year={2025},
month=oct,
pages={2043–2054}
}
This research was supported by NSF Award 2533162.